Pianoroll-Event: A Novel Score Representation for Symbolic Music
*Equal contribution. †Corresponding authors.
ICASSP 2026
Abstract
Symbolic music representation is a fundamental challenge in computational musicology. While grid-based representations effectively preserve pitch-time spatial correspondence, their inherent data sparsity leads to low encoding efficiency. Discrete-event representations achieve compact encoding but fail to adequately capture structural invariance and spatial locality. To address these complementary limitations, we propose Pianoroll-Event, a novel encoding scheme that describes pianoroll representations through events, combining structural properties with encoding efficiency while maintaining temporal dependencies and local spatial patterns. Specifically, we design four complementary event types: Frame Events for temporal boundaries, Gap Events for sparse regions, Pattern Events for note patterns, and Musical Structure Events for musical metadata. Pianoroll-Event strikes an effective balance between sequence length and vocabulary size, improving encoding efficiency by 1.36× to 7.16× over representative discrete sequence methods. Experiments across multiple autoregressive architectures show models using our representation consistently outperform baselines in both quantitative and human evaluations.
Pianoroll-Event Data Representation
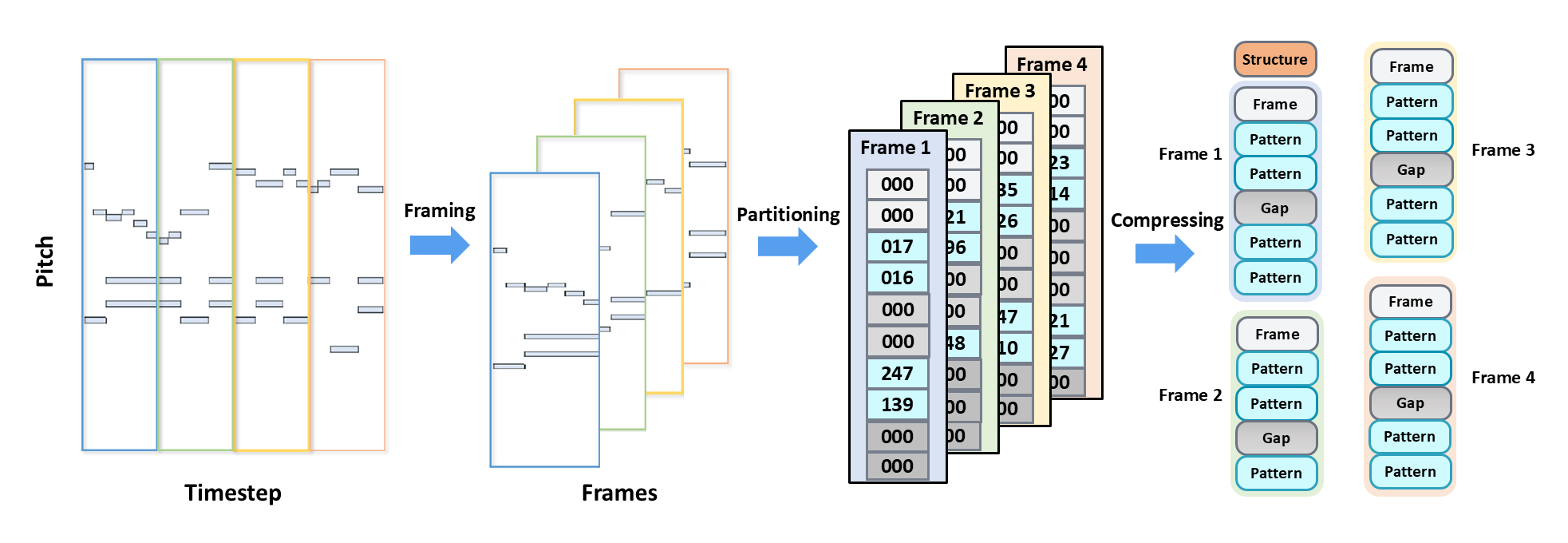
The process of converting pianoroll representation into pianoroll-events. Through frame segmentation, partitioning, and compression operations, the pianoroll is transformed into a sequence of pianoroll-events containing diverse event types.
Encoding Efficiency Comparison
| Method | ℓ (Length) | V (Vocab) | BDI ↓ | vs. Ours ↓ |
|---|---|---|---|---|
| Ours | 749.8 | 347 | 1.048 | 1.00× |
| REMI | 1339.7 | 330 | 3.261 | 3.11× |
| MIDILike | 1398.9 | 448 | 4.143 | 3.96× |
| REMI-BPE | 317.8 | 20,000 | 1.429 | 1.36× |
| ABC Notation | 2575.0 | 128 | 7.504 | 7.16× |
Table 1. Encoding efficiency comparison. BDI (Budget-Aware Difficulty Index) = ℓ² × √V captures both computational complexity and vocabulary size. Lower is better.
Generated Songs
The following musical pieces are generated by our best-performing Transformer decoder model with Llama architecture, conditioned only on time signature and BPM. The results demonstrate the considerable potential of our representation method.